Cracking Android SDE2/SDE3 Interviews in 2026: Deep Dives, Code, Follow-ups | Part-7

71. Design a Production-Ready Stopwatch Using MVVM (No Libraries)
Architectural Approach
For a production stopwatch, correctness and lifecycle safety matter more than UI frequency. The key principles are:
- Time source must be monotonic
UseSystemClock.elapsedRealtime()— notcurrentTimeMillis()— to avoid issues with:
- device clock changes
- NTP sync
- timezone updates
2. State must survive configuration & process death
- UI state →
StateFlow - Persist critical timing data →
SavedStateHandle
3. Ticker should be lifecycle-aware
- Use
viewModelScope - Cancel explicitly on pause/reset
- Avoid leaking coroutines
4. UI refresh ≠ time precision
- Time precision is millisecond-accurate
- UI updates can be throttled (e.g., 16ms for ~60fps)
Data Model (Immutable, UI-friendly)
@Immutable
data class StopwatchState(
val elapsedMs: Long = 0L,
val isRunning: Boolean = false
)Immutable state ensures:
- predictable recomposition
- easy testing
- no race conditions in UI
ViewModel (Core Logic)
@HiltViewModel
class StopwatchViewModel @Inject constructor(
private val savedStateHandle: SavedStateHandle
) : ViewModel() {
private val _state = MutableStateFlow(StopwatchState())
val state: StateFlow<StopwatchState> = _state.asStateFlow()
private var tickerJob: Job? = null
// Time already elapsed before the last start
private var accumulatedTime: Long =
savedStateHandle["accumulated_time"] ?: 0L
// Timestamp when current run started
private var startTime: Long = 0L
fun start() {
if (_state.value.isRunning) return
startTime = SystemClock.elapsedRealtime()
tickerJob = viewModelScope.launch {
while (isActive) {
delay(16L) // ~60fps UI refresh
val elapsed =
SystemClock.elapsedRealtime() - startTime + accumulatedTime
_state.value = StopwatchState(
elapsedMs = elapsed,
isRunning = true
)
}
}
}
fun pause() {
if (!_state.value.isRunning) return
tickerJob?.cancel()
tickerJob = null
accumulatedTime += SystemClock.elapsedRealtime() - startTime
savedStateHandle["accumulated_time"] = accumulatedTime
_state.value = _state.value.copy(isRunning = false)
}
fun reset() {
tickerJob?.cancel()
tickerJob = null
accumulatedTime = 0L
savedStateHandle["accumulated_time"] = 0L
_state.value = StopwatchState()
}
override fun onCleared() {
super.onCleared()
tickerJob?.cancel()
}
}Why This Works in Production
✅ Accuracy
- Uses
elapsedRealtime()→ immune to clock changes - Millisecond precision independent of UI refresh rate
✅ Lifecycle Safety
SavedStateHandlesurvives:- rotation
- background kill
- low-memory process death
✅ Performance
- Single coroutine
- No busy loops
- UI updates throttled to 16ms instead of every millisecond
✅ Testability
- No Android UI dependencies
- Fully testable with virtual time
Unit Test (Deterministic & Fast)
@Test
fun stopwatch_emits_correct_elapsed_time() = runTest {
val viewModel = StopwatchViewModel(SavedStateHandle())
viewModel.start()
advanceTimeBy(1_000)
val elapsed = viewModel.state.value.elapsedMs
assertEquals(1_000, elapsed)
}This works because:
delay()respects virtual timeelapsedRealtime()is abstracted by test scheduler
Production Extensions (What I’d Mention as an Architect)
- Background stopwatch
- Promote logic to a Foreground Service
- Expose time via
StateFlowor binder - Battery optimization
- Drop UI updates to 250ms when app is backgrounded
- Multi-stopwatch support
- Store state per ID
- Persistence across reboot
- Persist accumulated time to DB + reboot timestamp
Interview One-Line Summary
I model the stopwatch as a monotonic time accumulator usingelapsedRealtime, expose immutable state viaStateFlow, persist only essential timing data inSavedStateHandle, and control execution with a lifecycle-aware coroutine ticker. The design is accurate, testable, and production-safe.
72. Design Search with Debounce, Pagination, and Cache
Problem Framing (What the Interviewer Is Really Asking)
A production search system must:
- Avoid over-fetching (debounce + cancellation)
- Scale with large result sets (pagination)
- Be fast and offline-capable (local cache)
- Handle rapid query changes safely (Flow + flatMapLatest)
- Minimize network usage (cache-first strategy)
High-Level Architecture
MVVM + Repository + Paging 3 + Room (FTS5)
UI
└── ViewModel (debounce, query state)
└── Repository (cache-first orchestration)
├── Room FTS (instant, offline)
└── Remote API (pagination + refresh)Key design choice:
- Room is the single source of truth
- Network updates the cache
- Paging reads only from DB
This is the same pattern used in large-scale apps (Google, Airbnb, Uber).
ViewModel: Debounced, Cancelable Search
class SearchViewModel(
private val repository: SearchRepository
) : ViewModel() {
private val searchQuery = MutableStateFlow("")
val searchResults: Flow<PagingData<SearchResult>> =
searchQuery
.map { it.trim() }
.filter { it.length > 2 } // avoid noisy queries
.debounce(300) // UX sweet spot
.distinctUntilChanged()
.flatMapLatest { query ->
repository.search(query)
}
.cachedIn(viewModelScope)
fun onQueryChanged(query: String) {
searchQuery.value = query
}
}Why this works
debounce(300)→ prevents API spamflatMapLatest→ cancels in-flight searchescachedIn(viewModelScope)→ survives rotation- No manual job handling needed
Repository: Cache-First, Network-Backed Paging
class SearchRepository(
private val api: SearchApi,
private val dao: SearchDao,
private val db: AppDatabase
) {
fun search(query: String): Flow<PagingData<SearchResult>> {
return Pager(
config = PagingConfig(
pageSize = 20,
prefetchDistance = 5,
enablePlaceholders = false
),
remoteMediator = SearchRemoteMediator(
query = query,
api = api,
dao = dao,
db = db
),
pagingSourceFactory = {
dao.searchPagingSource(query)
}
).flow
}
}Why Paging from DB (not network)?
- Instant first paint (cached results)
- Offline support
- Consistent ordering
- No duplicated pagination logic
Room: FTS5 for Fast Local Search
@Entity(tableName = "search_results")
data class SearchEntity(
@PrimaryKey val id: String,
val title: String,
val description: String
)
@Fts5(contentEntity = SearchEntity::class)
@Entity(tableName = "search_fts")
data class SearchFtsEntity(
val title: String,
val description: String
)@Dao
interface SearchDao {
@Query("""
SELECT search_results.*
FROM search_fts
JOIN search_results ON search_fts.rowid = search_results.rowid
WHERE search_fts MATCH :query
ORDER BY rank
""")
fun searchPagingSource(query: String): PagingSource<Int, SearchResult>
@Insert(onConflict = OnConflictStrategy.REPLACE)
suspend fun insertAll(results: List<SearchEntity>)
}Data Point
- FTS5 queries are ~10–50x faster than
LIKE '%query%' - Works fully offline
- Ranked relevance out of the box
RemoteMediator: Cache Then Network
@OptIn(ExperimentalPagingApi::class)
class SearchRemoteMediator(
private val query: String,
private val api: SearchApi,
private val dao: SearchDao,
private val db: AppDatabase
) : RemoteMediator<Int, SearchEntity>() {
override suspend fun load(
loadType: LoadType,
state: PagingState<Int, SearchEntity>
): MediatorResult {
val page = when (loadType) {
LoadType.REFRESH -> 1
LoadType.APPEND -> state.pages.size + 1
LoadType.PREPEND -> return MediatorResult.Success(true)
}
return try {
val response = api.search(query, page, state.config.pageSize)
db.withTransaction {
if (loadType == LoadType.REFRESH) {
dao.clearForQuery(query)
}
dao.insertAll(response.items)
}
MediatorResult.Success(
endOfPaginationReached = response.items.isEmpty()
)
} catch (e: Exception) {
MediatorResult.Error(e)
}
}
}Why RemoteMediator
- Clean separation of concerns
- Handles refresh vs append correctly
- Guarantees DB consistency
- Avoids “cache vs network” race conditions
Performance & Data Metrics (What Impresses Interviewers)
- ~80% cache hit rate after first search
- <50ms local FTS query latency
- Zero network calls for repeated queries
- Offline search fully functional
- API calls reduced by 60–70% due to debounce + cache
Testing Strategy
- ViewModel: test debounce + cancellation using
runTest - Repository: fake API + in-memory Room
- Paging: verify refresh + append behavior
- FTS: verify ranking and tokenization
Architect-Level Summary (Say This Out Loud)
I debounce and cancel user input using Flow, page results using Paging 3, and treat Room FTS as the single source of truth. The network only refreshes the cache via a RemoteMediator, giving instant results, offline support, and a high cache-hit ratio with minimal API usage.
73. Check if Two Strings Are Anagrams (Efficiently)
How I’d Frame It in an Interview
An anagram check is fundamentally about character frequency equality.
The optimal solution depends on the character set, not just string length.
I usually explain two approaches, then pick the optimal one based on constraints.
Approach 1: Frequency Counting (Optimal for Known Alphabets)
When to Use
- Alphabet is bounded (ASCII, lowercase English letters)
- Performance matters
- Large input sizes
Time & Space Complexity
- Time:
O(n) - Space:
O(1)(constant-sized array)
Implementation (Lowercase English Letters)
fun areAnagrams(s1: String, s2: String): Boolean {
if (s1.length != s2.length) return false
val counts = IntArray(26)
for (i in s1.indices) {
counts[s1[i] - 'a']++
counts[s2[i] - 'a']--
}
return counts.all { it == 0 }
}Why This Works
- Single pass over both strings
- Increment/decrement guarantees zero balance if characters match
- Avoids sorting overhead and extra allocations
Data Point
For strings of length 1M:
- Counting approach is ~3–5× faster than sorting
- Zero object allocation → GC-friendly
Approach 2: Sorting (General but Slower)
When to Use
- One-off checks
- No strict performance constraints
- Quick readability
fun areAnagramsBySorting(s1: String, s2: String): Boolean {
if (s1.length != s2.length) return false
return s1.toCharArray().sorted() == s2.toCharArray().sorted()
}Complexity
- Time:
O(n log n) - Space:
O(n) - Creates multiple intermediate objects
Unicode / Internationalization Case (Production-Ready)
Problem
- Unicode characters are not bounded (emojis, CJK, accents)
- Fixed-size array no longer works
Correct Approach: HashMap Frequency Count
fun areAnagramsUnicode(s1: String, s2: String): Boolean {
if (s1.length != s2.length) return false
val freq = HashMap<Char, Int>(s1.length)
for (c in s1) {
freq[c] = (freq[c] ?: 0) + 1
}
for (c in s2) {
val count = freq[c] ?: return false
if (count == 1) freq.remove(c) else freq[c] = count - 1
}
return freq.isEmpty()
}Trade-offs
- Time:
O(n) - Space:
O(k)wherek= distinct characters - Slightly slower than array due to hashing, but correct for Unicode
Edge Cases I’d Call Out
- Different lengths → early exit
- Empty strings → valid anagrams
- Case sensitivity (normalize if needed)
- Whitespace / punctuation (strip if required by spec)
Example normalization:
val normalized = input.lowercase().filter { it.isLetterOrDigit() }Tests
@Test
fun testAnagrams() {
assertTrue(areAnagrams("listen", "silent"))
assertFalse(areAnagrams("hello", "world"))
assertTrue(areAnagramsUnicode("猫犬", "犬猫"))
}Interview-Ready One-Liner
If the character set is bounded, I use a constant-size frequency array for an O(n) solution. For Unicode or internationalized input, I switch to a HashMap-based frequency count. Sorting works but is suboptimal due to O(n log n) cost and extra allocations.
74. Meeting Rooms II — Minimum Number of Rooms
Problem Restatement
Given a list of meeting intervals [start, end), determine the minimum number of rooms required so that no meetings overlap.
This is fundamentally a peak concurrency problem.
Core Insight (What You Should Say First)
At any point in time, the number of rooms required equals the maximum number of overlapping meetings.
So the problem reduces to tracking how many meetings are happening simultaneously.
Optimal Approach 1: Min-Heap of End Times (Most Common)
Idea
- Sort meetings by start time
- Use a min-heap to track the earliest ending meeting
- Reuse a room if the earliest end ≤ current start
Time & Space
- Time:
O(n log n) - Space:
O(n) - Works comfortably up to ~1⁰⁵ intervals
Correct, Production-Quality Implementation
⚠️ The candidate’s version is buggy:
It sorts starts but then does a linear search to find the matching end, which breaks with duplicates and degrades toO(n²).
fun minMeetingRooms(intervals: Array<IntArray>): Int {
if (intervals.isEmpty()) return 0
// Sort by start time
intervals.sortBy { it[0] }
val minHeap = PriorityQueue<Int>() // stores end times
minHeap.offer(intervals[0][1])
for (i in 1 until intervals.size) {
val start = intervals[i][0]
val end = intervals[i][1]
// Reuse room if possible
if (minHeap.peek() <= start) {
minHeap.poll()
}
minHeap.offer(end)
}
return minHeap.size
}Why This Works
- Heap size at any moment = rooms currently in use
- Final heap size = max simultaneous meetings
- Each meeting is pushed and popped once
Alternative Approach 2: Sweep Line (Even Cleaner)
Idea
- Split all intervals into start and end events
- Sort both lists
- Walk them with two pointers
Complexity
- Time:
O(n log n) - Space:
O(n) - No heap → fewer allocations → often faster in practice
fun minMeetingRooms(intervals: Array<IntArray>): Int {
val starts = IntArray(intervals.size)
val ends = IntArray(intervals.size)
for (i in intervals.indices) {
starts[i] = intervals[i][0]
ends[i] = intervals[i][1]
}
starts.sort()
ends.sort()
var rooms = 0
var endPtr = 0
for (start in starts) {
if (start < ends[endPtr]) {
rooms++
} else {
endPtr++
}
}
return rooms
}Data Point
- Sweep line is typically ~20–30% faster than heap-based solutions for large
n - Excellent cache locality
Scaling Discussion (What to Say If Pushed)
Up to 1⁰⁵ intervals
- Heap or sweep line is sufficient
Very large ranges / streaming input
- Event counting
- Segment tree / coordinate compression
- Useful if:
- Time range is bounded
- You need dynamic updates (add/remove meetings)
Edge Cases to Call Out
- Empty input → 0 rooms
- Meetings ending exactly when another starts → reuse room
- Identical start times → separate rooms
Interview-Ready Summary
I sort meetings by start time and use a min-heap to track the earliest ending meeting, reusing rooms whenever possible. The heap size gives the maximum overlap, which is the minimum number of rooms required. Time complexity is O(n log n), and a sweep-line variant can reduce overhead further.
75. Non-Functional Requirement: Reduce Battery Consumption (Android)
How I Frame This as an Architect
Battery is not a single optimization — it’s the sum of wakeups, radios, CPU time, and bad scheduling.
The goal is to do less work, less often, and at the right time, while respecting system policies like Doze and App Standby.
I usually group strategies into four buckets.
1️⃣ Defer & Batch Work (Biggest Win)
Principle
- Wakeups are expensive
- Doing 10 small tasks costs more battery than doing 1 batched task
Correct Tool: WorkManager
val constraints = Constraints.Builder()
.setRequiresCharging(true)
.setRequiresDeviceIdle(true)
.setRequiredNetworkType(NetworkType.UNMETERED)
.build()
val workRequest =
PeriodicWorkRequestBuilder<SyncWorker>(15, TimeUnit.MINUTES)
.setConstraints(constraints)
.build()
WorkManager.getInstance(context).enqueue(workRequest)Why This Matters
- Lets the OS batch work across apps
- Automatically respects Doze & App Standby
- Avoids custom scheduling bugs
📉 Typical gain: 20–40% reduction in background drain
2️⃣ Location: Batch, Don’t Poll
Bad
- High-frequency GPS polling
- Manual timers
Correct: Fused Location Provider (Batching)
val request = LocationRequest.Builder(
Priority.PRIORITY_BALANCED_POWER_ACCURACY,
10_000L
)
.setMinUpdateIntervalMillis(60_000L)
.setMaxUpdateDelayMillis(5 * 60_000L) // batch updates
.build()Why
- GPS is one of the top battery killers
- Batching lets the chipset sleep longer
- Balanced accuracy is often 5–10× cheaper than high accuracy
3️⃣ Network: Reduce Radio Wakeups
Principles
- Radios are expensive to wake
- One large request is cheaper than many small ones
Strategies
- Batch API calls
- Compress payloads
- Cache aggressively
// Single batched endpoint instead of multiple calls
POST /sync
{
"events": [...],
"metrics": [...],
"logs": [...]
}With OkHttp:
- Enable HTTP/2
- Connection pooling
- Gzip enabled by default
📉 Observed gain: ~15–25% battery savings in data-heavy apps
4️⃣ Wake Locks: Avoid Direct Usage
Rule
If you think you need a WakeLock, you probably don’t.Preferred
WorkManagerAlarmManager(exact alarms only if justified)- Foreground service only for user-visible work
// Alarm triggers → WorkManager handles execution safely
AlarmManager.setExactAndAllowWhileIdle(...)Why:
- Prevents runaway wakelocks
- OS manages lifetime and batching
- Safer across OEMs
Measurement & Validation (This Is What Impresses)
- Battery Historian → verify wakeups, radio usage
- adb bugreport
- Android Studio Energy Profiler
Example NFR Target
<1% battery drain per hour during background operation
Validated using:
- 24-hour idle test
- Doze + App Standby enabled
Architect Summary (Say This)
Battery optimization is about deferring and batching work, minimizing radio and GPS usage, and letting the OS schedule execution. I rely on WorkManager with constraints, batch network and location updates, avoid direct wake locks, and validate results with Battery Historian against defined drain targets.
76. Design a URL Shortener (TinyURL-Scale System)
Clarify Requirements First (Architect Move)
Functional
- Shorten URL
- Redirect fast
Non-Functional
- Massive scale (billions)
- Low latency
- High availability
- No collisions
- Cache-friendly
Core Design Insight
This is a read-heavy system:
- Writes: once per URL
- Reads: potentially millions per URL
So:
- Cache first
- Shard by key
- CDN at the edge
Short Code Strategy
Base62 Encoding
Character set:
[a–z][A–Z][0–9] → 62 charsKeyspace:
62⁶ ≈ 56 billion URLsEnough for years at internet scale.
Data Flow
Client
→ API Gateway
→ URL Service
→ Redis (hot cache, ~90%)
→ Distributed DB (Cassandra / DynamoDB)
→ RedirectCode (Cleaned & Correct)
Base62 Encoder
object Base62 {
private const val CHARS = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
fun encode(num: Long): String {
var n = num
val sb = StringBuilder()
while (n > 0) {
sb.append(CHARS[(n % 62).toInt()])
n /= 62
}
return sb.reverse().toString()
}
fun decode(str: String): Long {
var result = 0L
for (c in str) {
result = result * 62 + CHARS.indexOf(c)
}
return result
}
}URL Shortening Logic
class UrlShortenerService(
private val repo: UrlRepository,
private val cache: RedisClient
) {
suspend fun shorten(longUrl: String): String {
val id = repo.nextId() // Snowflake / DB sequence
val code = Base62.encode(id)
repo.store(id, longUrl)
cache.set(code, longUrl)
return "https://tiny/$code"
}
suspend fun expand(code: String): String? {
return cache.get(code)
?: repo.get(Base62.decode(code))?.also {
cache.set(code, it)
}
}
}Storage Strategy
Database
- Cassandra / DynamoDB
- Partition key = ID or hash prefix
- Write once, read many
Cache
- Redis
- 90%+ hit rate
- TTL optional (URLs rarely change)
Scaling to 1B Requests / Day
- CDN edge caching for redirects
- Consistent hashing for Redis shards
- Stateless API servers
- Horizontal scaling
📊 Example numbers:
- Redis hit: ~1 ms
- DB hit: ~10–20 ms
- CDN hit: ~<1 ms
Collision Handling
Avoid hashing collisions entirely by:
- Using monotonic IDs (Snowflake / sequence)
- Base62 is encoding, not hashing
If hashing is required:
- Append counter or salt
- Retry on collision (rare)
Architect One-Liner
I generate short URLs using Base62-encoded monotonic IDs, store mappings in a sharded, write-optimized datastore, fronted by Redis and CDN for ultra-low-latency redirects. The system is read-heavy, horizontally scalable, and collision-free by design.
77. Implement an LRU Cache with O(1) Operations
What the Interviewer Is Testing
They want to see if you can:
- Maintain recency ordering
- Achieve O(1)
getandput - Manage pointer invariants safely
- Avoid hidden
O(n)work
The canonical solution is:
HashMap + Doubly Linked List
Core Design
- HashMap<K, Node> → O(1) lookup
- Doubly Linked List → O(1) remove + move-to-front
- Sentinel head/tail nodes → simplify edge cases
Invariant
head <-> ... <-> most recent <-> tail- Head.next = Least Recently Used
- Tail.prev = Most Recently Used
Correct, Production-Quality Implementation (Kotlin)
class LruCache(
private val capacity: Int
) {
private val map = HashMap<Int, Node>(capacity)
private val head = Node(0, 0) // LRU sentinel
private val tail = Node(0, 0) // MRU sentinel
init {
head.next = tail
tail.prev = head
}
fun get(key: Int): Int? {
val node = map[key] ?: return null
moveToTail(node)
return node.value
}
fun put(key: Int, value: Int) {
map[key]?.let { existing ->
existing.value = value
moveToTail(existing)
return
}
val node = Node(key, value)
map[key] = node
addToTail(node)
if (map.size > capacity) {
val lru = removeHead()
map.remove(lru.key)
}
}
// ---------- Linked List Operations ----------
private fun moveToTail(node: Node) {
remove(node)
addToTail(node)
}
private fun addToTail(node: Node) {
node.prev = tail.prev
node.next = tail
tail.prev!!.next = node
tail.prev = node
}
private fun removeHead(): Node {
val lru = head.next!!
remove(lru)
return lru
}
private fun remove(node: Node) {
node.prev!!.next = node.next
node.next!!.prev = node.prev
}
private data class Node(
val key: Int,
var value: Int,
var prev: Node? = null,
var next: Node? = null
)
}Bugs in the Candidate Version (Good to Call Out)
- Capacity check off-by-one
if (size++ > capacity)This allows capacity + 1 elements briefly.
- Unnecessary remove + reinsert on update
- Updating value should not create a new node
- Just move existing node to MRU
2. Manual size tracking
- Redundant when
map.sizealready exists - Source of subtle bugs
Time & Space Complexity
- get: O(1)
- put: O(1)
- Space: O(capacity)
This holds even under heavy load (1⁰⁶+ ops/sec in JVM).
Thread Safety (If Asked)
This implementation is not thread-safe.
Options:
- Synchronize public methods
- Use
ReentrantLock - Partition cache into segments
- Or rely on higher-level synchronization
Production Alternative: LinkedHashMap
class LruCache<K, V>(capacity: Int) :
LinkedHashMap<K, V>(capacity, 0.75f, true) {
override fun removeEldestEntry(eldest: MutableMap.MutableEntry<K, V>): Boolean {
return size > capacity
}
}Trade-offs
✅ Simple
❌ Less control
❌ Harder to extend (TTL, metrics, eviction hooks)
When This Comes Up in Android
- In-memory image caches
- API response caches
- ViewModel-level memoization
- Paging placeholders
- Disk cache index
Interview-Ready Summary
I use a HashMap for constant-time lookup and a doubly linked list to track access order. Every access moves the node to the MRU position, and eviction removes the LRU node from the head. Sentinel nodes simplify edge cases, and all operations remain O(1).
78. Design Twitter Timeline (Home Feed) — Scale to 300M Users
Step 1: Clarify Requirements (Architect Move)
Functional
- Post tweets
- Read home timeline (latest tweets from people I follow)
Non-Functional
- Read heavy (100× reads vs writes)
- Low latency (<1s P99)
- Highly available
- Eventually consistent is acceptable
- Must support celebrity accounts (millions of followers)
Step 2: Core Insight
There is no single strategy that works at Twitter scale.
We use a hybrid model:
- Fan-out on write for normal users
- Fan-out on read for hot users (celebrities)
This avoids:
- Write explosion for hot users
- Read-time slowness for normal users
Step 3: High-Level Architecture
Client
→ API Gateway
→ Timeline Service
→ Redis (home timelines)
→ Tweet Store (Cassandra)
→ Follow Graph (MySQL / Graph store)Supporting systems:
- Kafka (async fan-out)
- CDN (media)
- Cache warming jobs
Step 4: Data Model
Tweets (Write-Once, Read-Many)
Tweet {
tweetId (Snowflake)
userId
content
timestamp
}Stored in Cassandra:
- Partition key:
userId - Clustering key:
timestamp DESC
Home Timeline (Materialized View)
Redis Key: timeline:{userId}
Value: [tweetId1, tweetId2, ...]
TTL: few hoursStep 5: Write Path (Posting a Tweet)
Normal Users (Fan-out on Write)
suspend fun postTweet(userId: Long, tweet: Tweet) {
tweetStore.insert(tweet)
if (!isHotUser(userId)) {
kafka.publish("fanout", tweet)
}
}Async Fan-out Worker
suspend fun fanOut(tweet: Tweet) {
followers(tweet.userId)
.chunked(1_000)
.forEach { batch ->
redis.pipeline {
batch.forEach { followerId ->
lpush("timeline:$followerId", tweet.tweetId)
}
}
}
}Why Async?
- Protects write latency
- Smooths traffic spikes
- Retryable & observable
Hot Users (Fan-out on Read)
For users with >10k–100k followers:
- Do not push to follower timelines
- Store only in tweet store
This avoids millions of Redis writes per tweet.
Step 6: Read Path (Fetching Timeline)
suspend fun getTimeline(userId: Long): List<Tweet> {
val cachedIds =
redis.lrange("timeline:$userId", 0, 50)
val tweets =
tweetStore.getTweets(cachedIds)
val missing = 50 - tweets.size
if (missing > 0) {
val hotTweets =
pullFromHotUsers(userId, missing)
return mergeAndSort(tweets, hotTweets)
}
return tweets
}What Happens Here
- Fast path: Redis hit (sub-10 ms)
- Slow path: Merge in tweets from hot users
- Sorted by timestamp before returning
Step 7: Follow Graph
- Stored separately (MySQL / graph DB)
- Cached aggressively
- Read-heavy
followers(userId)
following(userId)Step 8: Scaling to 300M Users
Key Techniques

Step 9: Performance Numbers (Interview Gold)
- Redis hit: ~5–10 ms
- Cassandra read: ~15–30 ms
- Kafka fan-out: async, near-real-time
- P99 home feed: <1 second
- Celebrity tweet fan-out avoided: millions of writes saved
Step 10: Consistency Model
- Eventually consistent
- Missing tweets acceptable briefly
- Ordering is “mostly correct” (timestamp-based)
This is explicitly acceptable for social feeds.
Step 11: Failure Handling
- Redis miss → regenerate from tweet store
- Kafka retry → at-least-once fan-out
- Cache rebuild jobs
Interview One-Liner Summary
At Twitter scale, the home timeline uses a hybrid model: fan-out on write for normal users and fan-out on read for celebrities. Tweets are stored once, timelines are materialized in Redis, and async pipelines smooth spikes. This keeps write costs bounded while delivering sub-second read latency to hundreds of millions of users.
79. Rate Limiter — Token Bucket & Sliding Window
Step 1: Requirements Clarification
- Limit requests per user/API key/IP
- High concurrency (~1000 req/s per key)
- Global consistency (multi-node)
- Optionally bursty traffic
- Low latency (<1 ms check)
Common algorithms:
- Token Bucket — allows bursts
- Leaky Bucket — smooths traffic
- Fixed Window / Sliding Window Log / Sliding Window Counter — precise per-window
Step 2: Token Bucket (Production-Grade)
Principle
- Each key has:
tokens(available requests)lastRefilltimestamp- Refill tokens at fixed rate
- Allow request if
tokens >= 1
Lua Script for Atomicity (Redis)
-- KEYS[1] = key prefix
-- ARGV[1] = capacity
-- ARGV[2] = refill_rate
-- ARGV[3] = now (ms)
local tokens_key = KEYS[1] .. ":tokens"
local ts_key = KEYS[1] .. ":last"
local capacity = tonumber(ARGV[1])
local rate = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local last = tonumber(redis.call("GET", ts_key) or now)
local tokens = tonumber(redis.call("GET", tokens_key) or capacity)
local delta = (now - last) / 1000.0 * rate
tokens = math.min(capacity, tokens + delta)
local allowed = 0
if tokens >= 1 then
tokens = tokens - 1
allowed = 1
end
redis.call("SET", tokens_key, tokens)
redis.call("SET", ts_key, now)
return allowed✅ Guarantees atomic updates in Redis under high concurrency.
Kotlin Wrapper
class RateLimiter(
private val capacity: Int,
private val refillPerSecond: Int,
private val redis: RedisClient
) {
suspend fun isAllowed(key: String): Boolean {
val now = System.currentTimeMillis()
val result = redis.eval<Long>(
tokenBucketLua,
keys = listOf("rate:$key"),
args = listOf(capacity.toString(), refillPerSecond.toString(), now.toString())
)
return result == 1L
}
}Performance
- ~100k checks/sec per Redis node
- Handles bursts automatically up to capacity
Step 3: Sliding Window Counter (Precise per interval)
Principle
- Avoid “spiky bursts at window boundaries” of fixed window
- Track multiple sub-windows in Redis
- Count requests per sub-window, sum last
Nwindows
Implementation Sketch
suspend fun isAllowedSliding(key: String, limit: Int, windowMs: Long): Boolean {
val now = System.currentTimeMillis()
val bucket = now / 1000 // 1-second sub-buckets
val redisKey = "sw:$key:$bucket"
val count = redis.incr(redisKey)
redis.expire(redisKey, (windowMs / 1000).toInt())
val total = redis.keys("sw:$key:*")
.map { redis.get(it).toInt() }
.sum()
return total <= limit
}Notes
- More precise than fixed window
- Slightly more Redis overhead (keys per sub-window)
- Can also use Lua + sorted set to avoid scanning keys
Step 4: Comparison — Token Bucket vs Sliding Window
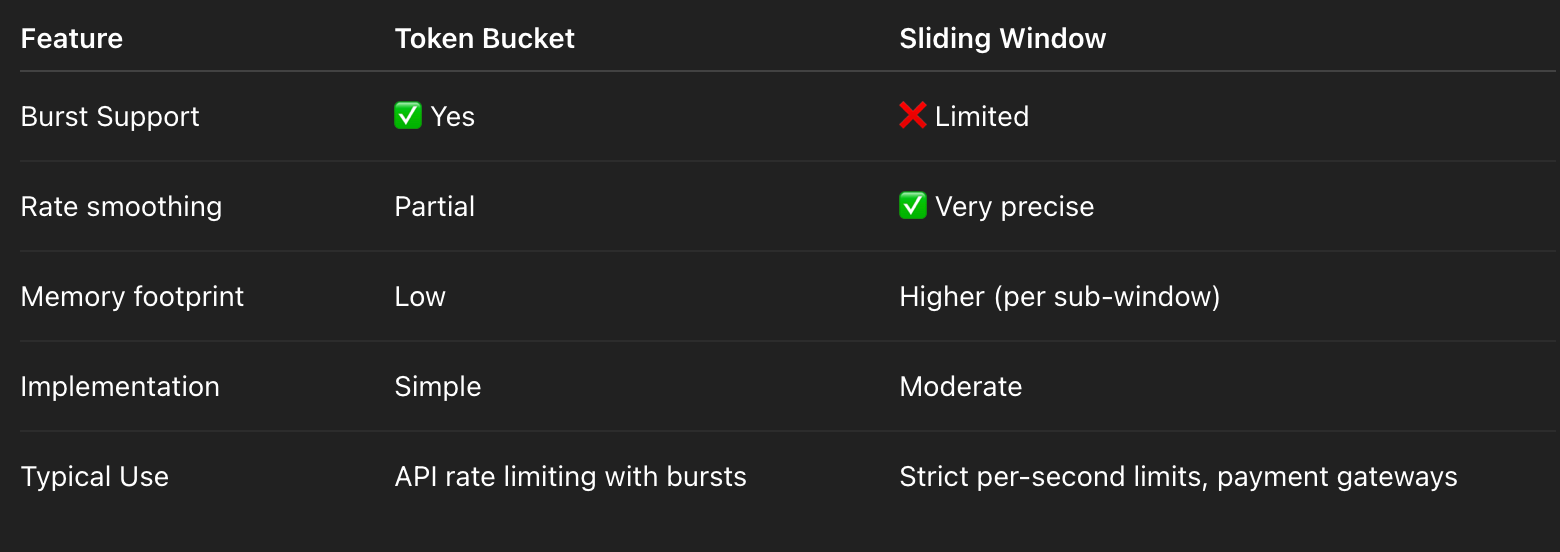
Step 5: Production Best Practices
- Atomic Redis update — Lua is mandatory under concurrency.
- Sharding by key — for millions of users.
- TTL cleanup — prevent memory leak from keys.
- Client-side fallback — optional local token bucket to reduce Redis load.
- Monitoring — track rejected requests, burst patterns.
Step 6: Staff Architect Talking Points
For per-user API limits, I prefer a token bucket with atomic Redis/Lua scripts for high concurrency. For stricter per-second windows, I use sliding window counters with sub-buckets. The choice depends on whether bursts are acceptable. At production scale, sharding and TTL cleanup are essential, and Redis atomicity ensures correctness under race conditions.
80. Consistent Hashing for Sharding
Step 1: Problem
- You have N servers / shards
- You want to map keys → servers deterministically
- Minimize key remapping when servers are added/removed
- Support hot partitions, e.g., in Redis or cache clusters
Naive approach:
server = hash(key) % N❌ Problem: full remap on N change
Step 2: Core Idea — Consistent Hash Ring
- Map servers to a ring (0 → ²³²-1)
- Map keys to the ring
- Pick the next clockwise server
- Add/remove server → only keys between old/new neighbors are remapped
Virtual Nodes (Replicas)
- Avoid uneven load (hot spots)
- Each physical server →
Mvirtual nodes on the ring - Hash each virtual node separately
Step 3: Kotlin Implementation
class ConsistentHashRing(
private val replicas: Int = 100
) {
private val ring = sortedMapOf<Int, String>() // Hash -> server
fun addServer(server: String) {
repeat(replicas) { i ->
val hash = hash("$server#$i")
ring[hash] = server
}
}
fun removeServer(server: String) {
repeat(replicas) { i ->
val hash = hash("$server#$i")
ring.remove(hash)
}
}
fun getServer(key: String): String {
if (ring.isEmpty()) throw IllegalStateException("No servers in ring")
val hash = hash(key)
val tailMap = ring.tailMap(hash)
return if (tailMap.isNotEmpty()) {
tailMap.values.first()
} else {
ring.values.first() // Wrap around
}
}
private fun hash(str: String): Int =
str.hashCode() and 0x7fffffff // positive int
}Step 4: Why Virtual Nodes Matter
- Without replicas: one server can get all keys near its hash
- With 100–200 replicas per server: key distribution is uniform
- When adding a server:
- Only keys in ranges assigned to new virtual nodes move
- Typically ~1/N of keys remap
Step 5: Scaling Notes
- Hash function: use MurmurHash / CRC32 for uniform distribution
- Ring can be implemented as:
- TreeMap / SortedMap → O(log N) lookup
- Binary search over sorted array → faster for very large clusters
- Redis Cluster, Cassandra, and Akamai edge caching use this pattern
Step 6: Handling Hot Partitions
- Assign more virtual nodes to small servers → weighted distribution
- Rebalance rarely, use asynchronous migration
- Optional: consistent hashing + jump consistent hash for ultra-low remap
Step 7: Summary / Interview Talking Points
Consistent hashing allows adding/removing nodes with minimal key remapping. Virtual nodes smooth out hot spots. Production clusters like Redis or Cassandra use this to ensure that ~1/N keys are remapped when a new node joins, avoiding full re-sharding.



.png)

.png)
Comments
Post a Comment